
This post is some of our thoughts on data management issues throughout the data lifecycle including loss of focus, upkeep priority, security access and disposition of data.

Many organizations are using the Data Cookbook to document and share their understanding of the data they store and use. Data issues tend to surface when data is reported out from one office to another, or from a central BI team to the organization at large, because there is an interest in or a need to interpret and use data at a particular time or for a certain reason. We commonly hear from clients that figures aren't consistent, or that even though discrepancies are expected they cannot be reconciled, or that it takes so long to verify and validate data that it's not useful as a planning, decision-making, or evaluation tool.
There are numerous explanations for this problem: poorly scoped data deliverables, improperly aggregated or analyzed data elements, a lack of clarity in the request, outdated security models, inappropriate delivery tools, hasty visualizations, and so on. One way or another, these are data management failures, and they sadly get magnified at critical times. However, data management problems exist throughout the data lifecycle, and in fact it's frequently the case that data issues that manifest during decision support actually occurred much further upstream.
A simple model of the data lifecycle looks like this: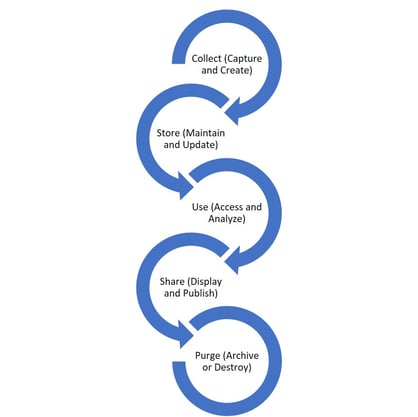
Here are some thoughts on data management issues throughout the data lifecycle:
As data collection has moved from mostly data entry to some mixture of data acquisition, data capture, and data entry, our practices have lost focus.
- Too much of what we collect isn't used. Much of what we collect might be useful, if we had an inkling what to do with it, but then again, it might not. Ceteris paribus, it's better to collect more data than to collect less, but we should always be asking at what cost and to what end. It's easier than ever to expand the what, but let's remember the why at the same time.
- Different offices collect different data, and even when they collect the same data they don't follow the same rules. In some cases this is simply a matter of some offices casting a wider data net, so to speak, but in the majority of our experience this has been more a matter of some offices commiting more training, resources, and oversight than others. A standard methodology for collecting data is a valuable tool here.
- The consistency - if not the accuracy and integrity - of data collected varies within offices (as well as across) as responsibility changes or as new data regimes emerge. As more and more systems are in use, we would expect even more confusion around what data is captured, by whom, in what form, and to what purpose. Data stewards would do well to set clear guidelines not only for their own offices and collections, but in coordination with other stewards and institutional data stakeholders.
Data storage and maintenance is often underfunded and underprioritized.
By data storage we don't mean the size of disk drives or backup methods, although in many organizations those needs could certainly be better funded and more visibly prioritized. Rather we're referring to steps and tasks involved in the persistence and upkeep of data in your collection.- Employees most directly responsible for these tasks tend to be comparatively low paid (take a look at address updates or other detailed transactions in your database, and see just how many of these are performed by clerical staff or high-turnover positions), and/or often minimally trained. (These employees are frequently actively involved in data collection as well.)
- Data is maintained in multiple systems, but typically without much rigor. For instance, the admissions office that manages a CRM has different rules and needs than the registrar's office managing enrollment data in the SIS, and oversight of the data transfer often lives outside both of these offices. So even if data collection for the CRM is strict and planned, that order can easily fall apart once it migrates.
- How is data kept current and clean? How are quality rules and metrics developed? What steps are taken when problems with operational data are discovered? It seems only reasonable that improvements to data maintenance will help avert problems that manifest later in data's lifespan.
Increasingly, data is critical to the functioning of modern organizations, but rather than focus on how it can and should be used, we focus too much on who can have access, and how much.
- Some organizations have not classified their data in any meaningful way, and access is structured around user requests and data steward whim. Whether data is accessed in a transactional system or as part of a BI infrastructure, this model is risky in two senses: one is that information will be shared inadvertently with people who shouldn't see it and who can do damage as a result; the other is that users have to guess where data might be, and, if they find it, how it got there, what it means, how best to use it, etc.
- More organizations go too far in the other direction, and data managers and data custodians work together to actively prohibit all but the most attenuated access to institutional data. See our earlier blog post for more thoughts on this practice.
- Still other organizations practice some form of security by obscurity, where users tend not to know whether certain pieces of data are even collected, where they might be stored if they are collected, and how or from whom to request access to them. In a previous blog we described how a data systems inventory is a jumping-off point to put an end to this useless practice.
Meaningful sharing of data, particularly of transformed and manipulated data, is tremendously challenging.
Data that isn't curated usually isn't understood consistently, and frequently we will see parallel or even competing data analysis efforts.
- It doesn't matter how proud you are of your report or dashboard if your underlying assumptions aren't visible, if the summarized data can't be quickly and definitively validated, if data consumers aren't aware of the extent or intent of data collected for analysis, if responsibility for data prior to its publication for analysis or action isn't clearly delineated.
- Similarly, no matter how extensive your BI architecture, no matter how high-tech your ETL and analytics tools, if your data management house hasn't been in order up to this point then a path to actual understanding of data publications won't really exist.
- Data curation doesn't begin when data moves from operating usage to strategic analysis; it really needs to begin at collection/inception.
Decisions about the final disposition of organizational data tend not to be final, or even real decisions.
- Shadow databases, and even sanctioned data sets, tend to live on, even when the data that originally sourced them has been retired or declared obsolete.
- Organizations generally hang on to too much data, even as it ages and decays, until they migrate to a new system, at which point there's often an arbitrary cutoff about what data gets ported to the new system and what gets left behind ("archived") in a system to which access is effectively shut off.
- As the relationship between an organization and the entities about which it collects and manages data changes, the rules often change without any formal notice. Which affects activities and decisions back at the point of capture and collection!
Data needs to be managed actively from the beginning to the end of its lifecycle. Those management activities take many forms including:
- strategic planning about systems and collections
- training and standards for storage and maintenance
- sensible security practices and access policies
- functional and technical documentation of data lineage
- skilled and accessible curation around report production, data analysis and visualization, and throughout the BI stack
- knowledgeable and empowered data stewards who can develop effective controls and work together to enact and update policies
You can buy tools to help with this work (such as the Data Cookbook). You can build your own, or customize existing products. But the problems listed above, and the data management activities necessary to prevent or address those problems, are procedural and cultural as well as technical. Our work with clients is predicated on this awareness, and we attempt to customize our training and support to identify and prioritize real needs and to develop pragmatic and immediately functional solutions. There is no magic potion, no panacea. But a data governance (data intelligence) strategy that considers the entire data life cycle, and appropriate data management practices at every point during that cycle, will result in higher quality data, data that can be used more effectively, by people and offices throughout your organization.
IData has a solution, the Data Cookbook, that can aid the employees and the organization in its data governance, reporting, data-driven decision making and data quality initiatives. IData also has experts that can assist with data governance, reporting, integration and other technology services on an as needed basis. Feel free to contact us and let us know how we can assist.
(Image Credit: StockSnap_5XAH7PI9TS_data_management_lifecycle_BP #1037)
